作为一名工业软件工程师,我一直在思考一个问题:能不能让AI像经验丰富的质量工程师一样,自主分析缺陷、追溯根因、给出处理建议?这篇文章记录了我用Agentic AI + RAG + Knowledge Graph构建工业质量智能助手的完整过程。
为什么要做这个项目
在我日常的AOI检测项目中,质量问题分析是一个高频场景:
- 产线上出现缺陷增多,工程师需要查检测标准、追溯供应商、分析变更记录
- 这些信息分散在质量文档、MES系统、追溯平台等多个地方
- 一个完整的分析过程通常需要30分钟到1小时
我的目标:让AI Agent自动完成这个过程——接收问题描述,自主决定先查什么再查什么,最终输出一份结构化的分析报告。
这不是一个ChatBot,而是一个能自主感知、规划、调用工具、执行、评估的Agentic AI系统。
整体架构
用户输入(缺陷描述 / 批次号 / 质量问题)
│
▼
┌─────────────────────────────────────────────┐
│ AI Agent (ReAct) │
│ LLM驱动的自主规划与路由 │
├─────────────┬──────────────┬────────────────┤
│ Tool 1 │ Tool 2 │ Tool 3 │
│ RAG检索 │ KG追溯 │ 报告生成 │
│ │ │ │
│ 质量标准 │ 缺陷→工站 │ 结构化 │
│ 文档库 │ →供应商 │ 分析报告 │
└─────────────┴──────────────┴────────────────┘
│
▼
结构化输出(根因分析 + 标准依据 + 改善建议)三个核心模块各自负责不同的事情:
RAG(检索增强生成) 解决"标准怎么说"的问题。把质量标准文档切片后存入向量数据库,用户提问时检索最相关的段落,让LLM基于真实文档回答,而不是凭空编造。
Knowledge Graph(知识图谱) 解决"为什么会这样"的问题。通过实体关系图,从缺陷出发,沿着"发生在→部件来自→最近变更"的关系链一路追溯到根因。
Agent(智能体) 是大脑。它不需要人告诉它先做什么后做什么,而是根据用户输入自主决定调用哪些工具、什么顺序、调用几次。
技术选型
| 组件 | 技术 | 选择理由 |
|---|---|---|
| LLM | GLM-4 (智谱AI) | OpenAI兼容接口,国内访问稳定 |
| Agent框架 | LangChain | 成熟的Tool/Agent生态,社区资源丰富 |
| 向量数据库 | FAISS | 轻量无依赖,本地运行足够 |
| Embedding模型 | all-MiniLM-L6-v2 | 384维向量,体积小速度快 |
| 知识图谱 | NetworkX | Python原生图库,Demo阶段够用 |
| 前端 | Streamlit | 零前端基础也能快速搭建Web界面 |
RAG模块——让AI有据可查
RAG的核心思想很简单:开卷考试。LLM自己的知识里没有我们公司的质量标准,那就把文档给它看,让它基于文档回答。
文档准备
我准备了三份模拟质量文档:
- 螺纹孔检测标准.txt:缺陷分级(A/B/C级)、判定阈值、检测方法、处理流程
- AOI缺陷分类指南.txt:表面缺陷和结构缺陷的分类标准、检测设备参数、产品颜色注意事项
- 产线异常处理流程.txt:异常分级、响应时间、根因分析方法、供应商管理流程
RAG四步流程
# 加载文档
loader = DirectoryLoader("data/quality_docs/", glob="*.txt",
loader_cls=TextLoader, loader_kwargs={"encoding": "utf-8"})
docs = loader.load()
# 文本分割——把长文档切成小段
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
chunks = splitter.split_documents(docs)
# 向量化——把文字转成数字,存入FAISS
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
vectorstore = FAISS.from_documents(chunks, embeddings)
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})这里有两个关键参数:
chunk_size=500 控制每段文本的长度。太长了检索精度下降,太短了上下文断裂。500字在中文质量文档场景下是一个不错的平衡点。
chunk_overlap=100 让相邻段落有100字重叠,防止关键信息正好被切断在两段之间。

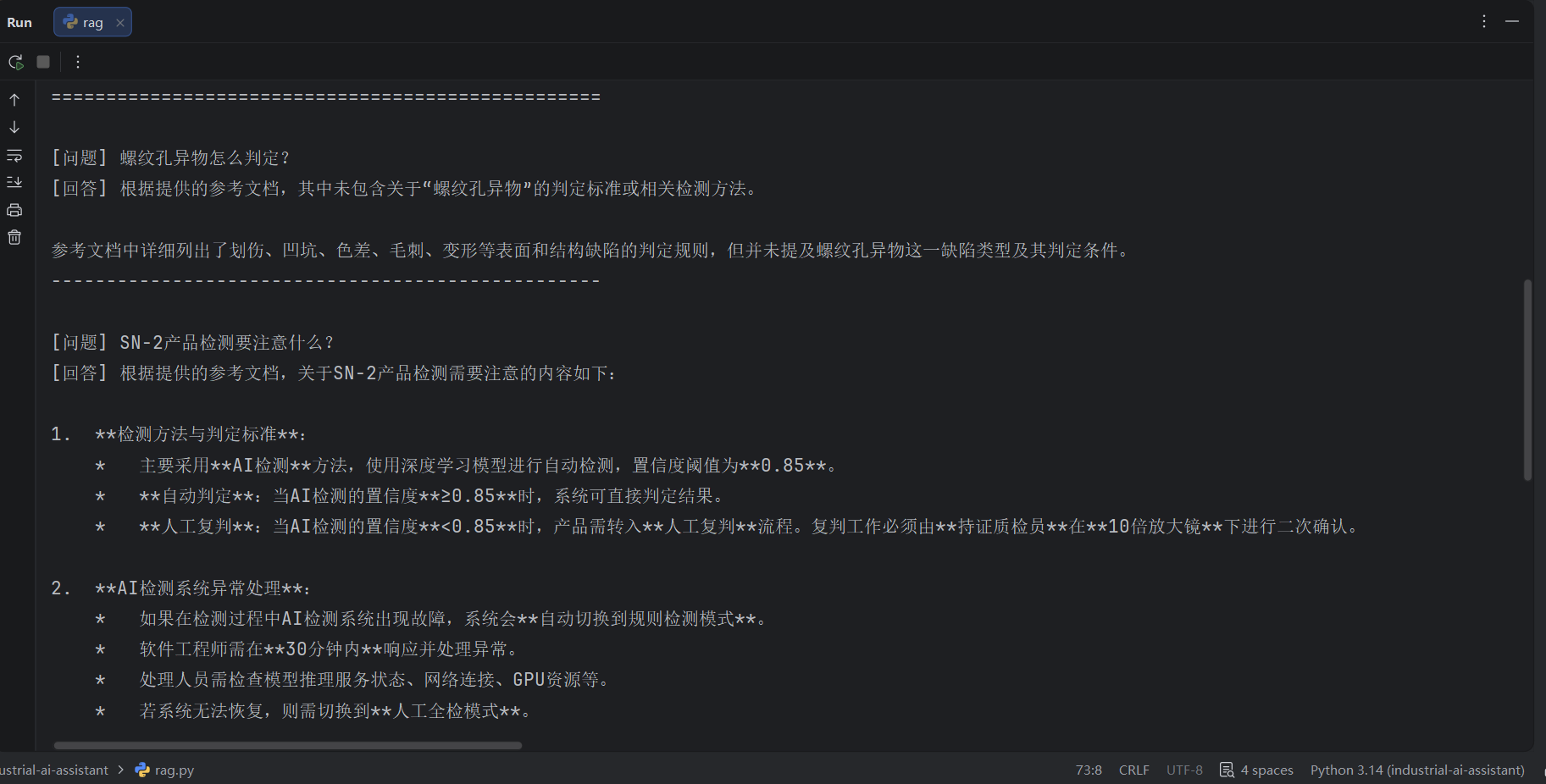
RAG检索效果
输入"螺纹孔异物怎么判定",系统从文档中检索到最相关的段落,LLM基于这些段落给出准确回答:
Knowledge Graph模块——链式追溯根因
KG的价值在于关系推理。数据库能告诉你"CNC-03工站有异物缺陷",但KG能告诉你"异物缺陷发生在CNC-03,CNC-03的部件来自供应商A,供应商A最近换了新批次刀具"——根因自动浮出来了。
构建知识图谱
import networkx as nx
G = nx.DiGraph()
# 节点:每个实体都是一个节点,带有属性
G.add_node("螺纹孔异物", type="defect", level="A级")
G.add_node("CNC-03", type="station", line="Line-2")
G.add_node("供应商A", type="supplier", contact="张经理")
G.add_node("2026-02刀具批次变更", type="change", date="2026-02-15")
# 边:实体之间的关系
G.add_edge("螺纹孔异物", "CNC-03", relation="detected_at")
G.add_edge("CNC-03", "供应商A", relation="parts_from")
G.add_edge("供应商A", "2026-02刀具批次变更", relation="recent_change")追溯查询
从缺陷节点出发,沿着边一路走下去:
def trace_defect(G, defect_type):
results = []
# 第1层:缺陷 → 工站
for station in G.successors(defect_type):
# 第2层:工站 → 供应商
for supplier in G.successors(station):
# 第3层:供应商 → 变更记录
for change in G.successors(supplier):
results.append(change) # 根因找到了运行追溯查询,输出如下:
=== 螺纹孔异物 追溯报告 ===
缺陷等级: A级
发生工站: CNC-03 (产线: Line-2)
供应商: 供应商A (联系人: 张经理)
⚠️ 最近变更: 2026-02刀具批次变更 (日期: 2026-02-15)
操作员: 张三 (班次: 白班)
操作员: 李四 (班次: 夜班)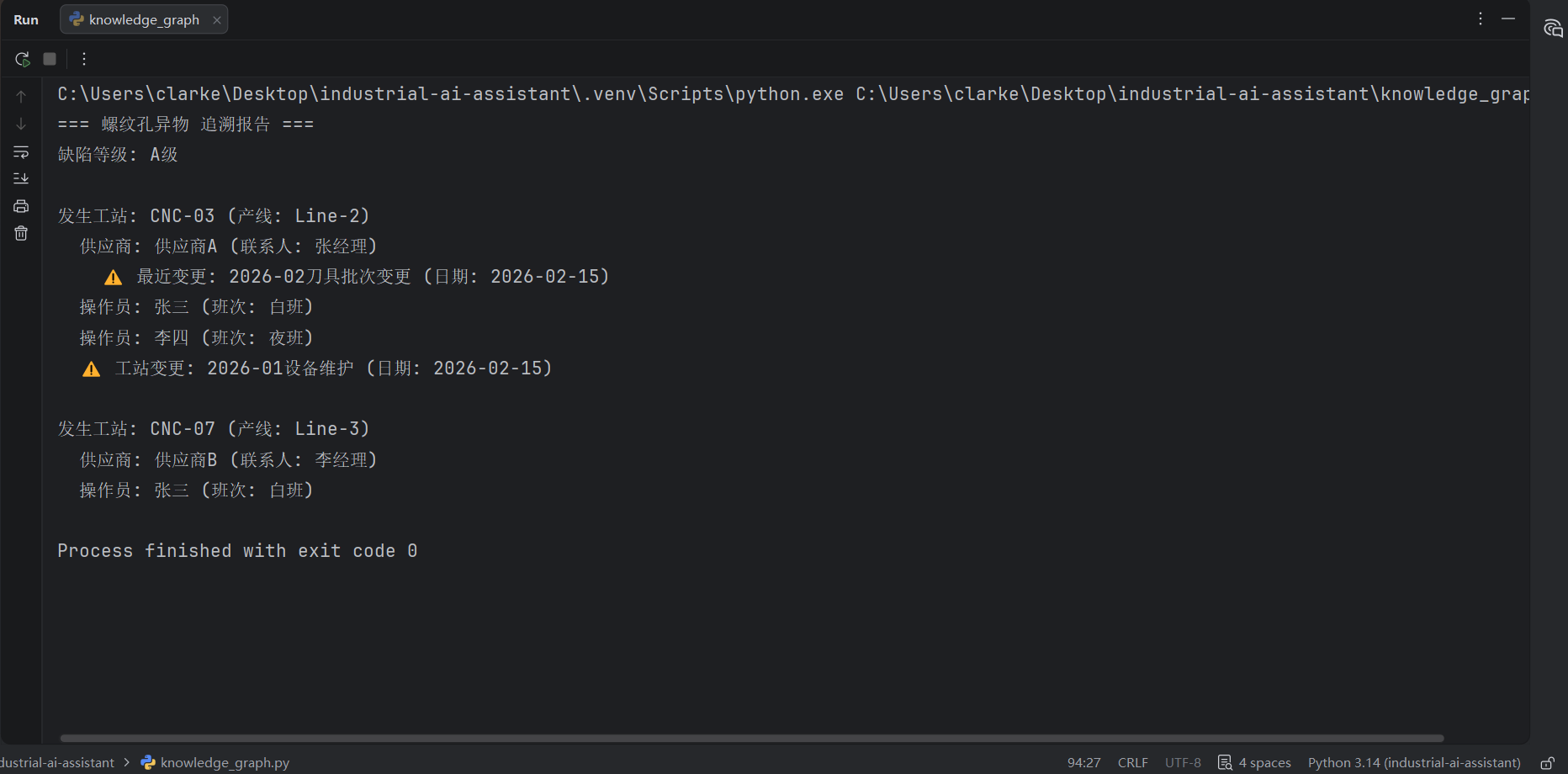
KG vs 数据库
同样的追溯,数据库需要写多层JOIN:
SELECT c.change_name, c.date
FROM defects d
JOIN stations s ON d.station = s.id
JOIN suppliers sp ON s.supplier = sp.id
JOIN changes c ON sp.id = c.supplier_id
WHERE d.type = '螺纹孔异物'KG只需要沿着边遍历。而且KG的优势是关系可以动态扩展——加一种新的关系类型不需要改表结构,加一个节点和一条边就行。
Agent模块——LLM自主决策
这是整个系统最核心的部分。Agent不是一个写死流程的脚本,而是一个LLM驱动的自主决策系统。
传统代码 vs Agent
// 传统写法:流程写死,每种问题都要预设处理路径
if (问题类型 == "缺陷分析")
{
查标准(); // 第1步写死
查工站(); // 第2步写死
生成报告(); // 第3步写死
}# Agent写法:LLM自己决定调什么、什么顺序
agent.invoke("CNC-03螺纹孔异物增多,分析原因")
# LLM自主决定:先追溯KG → 再查RAG标准 → 最后生成报告同一个Agent,面对不同的问题,调用的工具完全不同:
- "螺纹孔异物增多,分析原因" → KG追溯 + RAG查标准 + 生成报告
- "螺纹孔异物怎么判定" → 只调RAG查标准
- "CNC-03最近有什么变更" → 只调KG追溯
三个Tool的定义
@tool
def search_quality_standard(query: str) -> str:
"""从质量标准文档库中检索相关信息。当需要查询检测标准、判定依据、处理流程时调用。"""
docs = retriever.invoke(query)
return "\n\n".join([d.page_content for d in docs])
@tool
def trace_defect_source(defect_type: str) -> str:
"""根据缺陷类型追溯到工站、供应商和变更记录。当需要分析缺陷原因、追溯根因时调用。"""
return trace_defect(KG, defect_type)
@tool
def generate_report(analysis_data: str) -> str:
"""将分析数据整理成结构化质量分析报告。当已收集足够信息需要生成最终报告时调用。"""
response = llm.invoke(f"整理成质量报告:\n{analysis_data}")
return response.content这里的关键是docstring——LLM通过读这段描述来理解每个工具是干什么的。描述写得越精确,LLM选工具越准确。
Agent推理过程
tools = [search_quality_standard, trace_defect_source, generate_report]
llm_with_tools = llm.bind_tools(tools)bind_tools让LLM自动识别所有工具。不需要在prompt里手写工具描述,LLM从@tool的docstring自动获取信息。
Agent的核心是一个多轮循环:
def run_agent(user_input, max_rounds=5):
messages = [SystemMessage(content="..."), HumanMessage(content=user_input)]
for i in range(max_rounds):
response = llm_with_tools.invoke(messages)
messages.append(response)
# LLM没有调用工具 = 信息够了,直接输出
if not response.tool_calls:
return response.content
# LLM调用了工具 = 执行工具,把结果喂回去,继续下一轮
for tc in response.tool_calls:
result = tool_map[tc["name"]].invoke(...)
messages.append(ToolMessage(content=result, tool_call_id=tc["id"]))每一轮结束后,LLM评估"信息够不够"——不够就继续调工具,够了就输出最终答案。这就是Agent的Evaluation步骤。
实际运行效果
输入:"CNC-03工站最近螺纹孔异物缺陷增多,请帮我分析原因并给出处理建议"
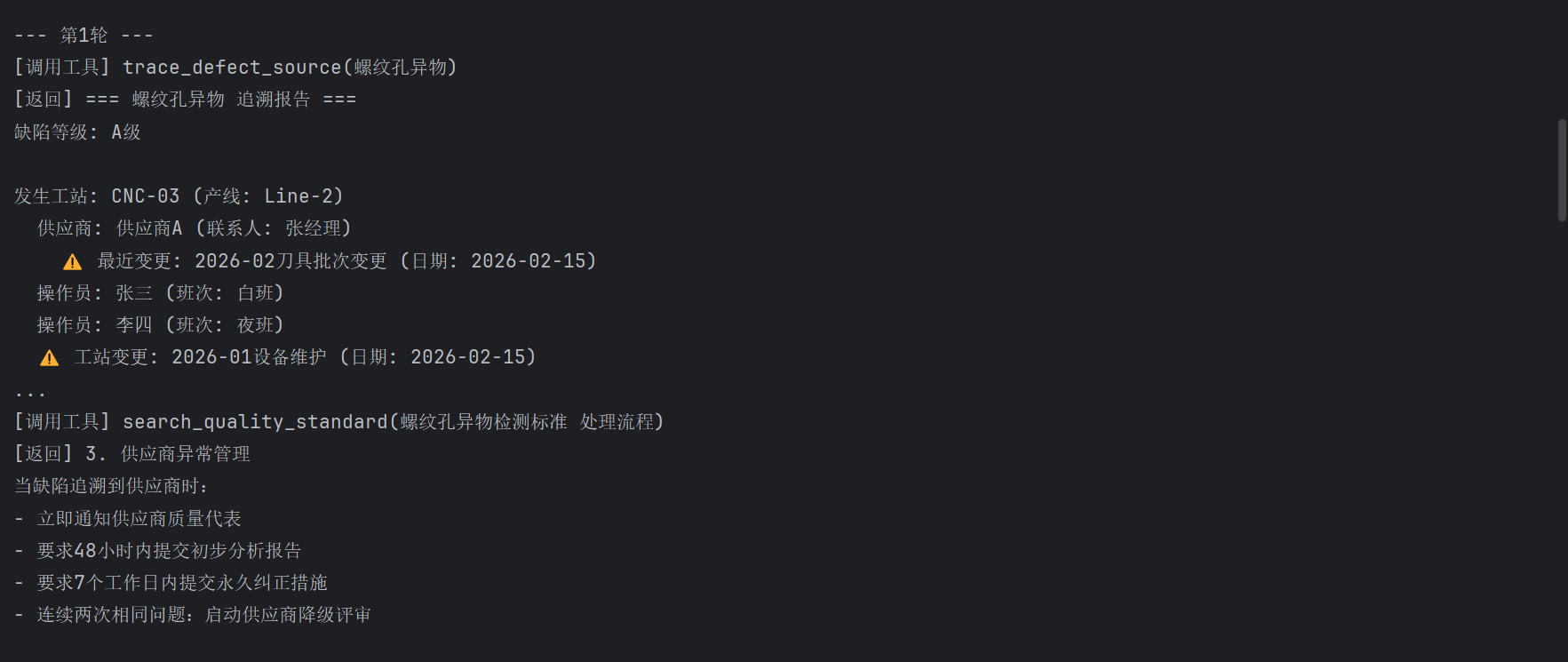
--- 第1轮 ---
[调用工具] trace_defect_source(螺纹孔异物)
[返回] 缺陷等级A级,发生在CNC-03,供应商A最近更换了新批次刀具...
--- 第2轮 ---
[调用工具] search_quality_standard(螺纹孔异物检测标准处理流程)
[返回] A级缺陷需立即隔离批次,通知产线主管,追溯供应商...
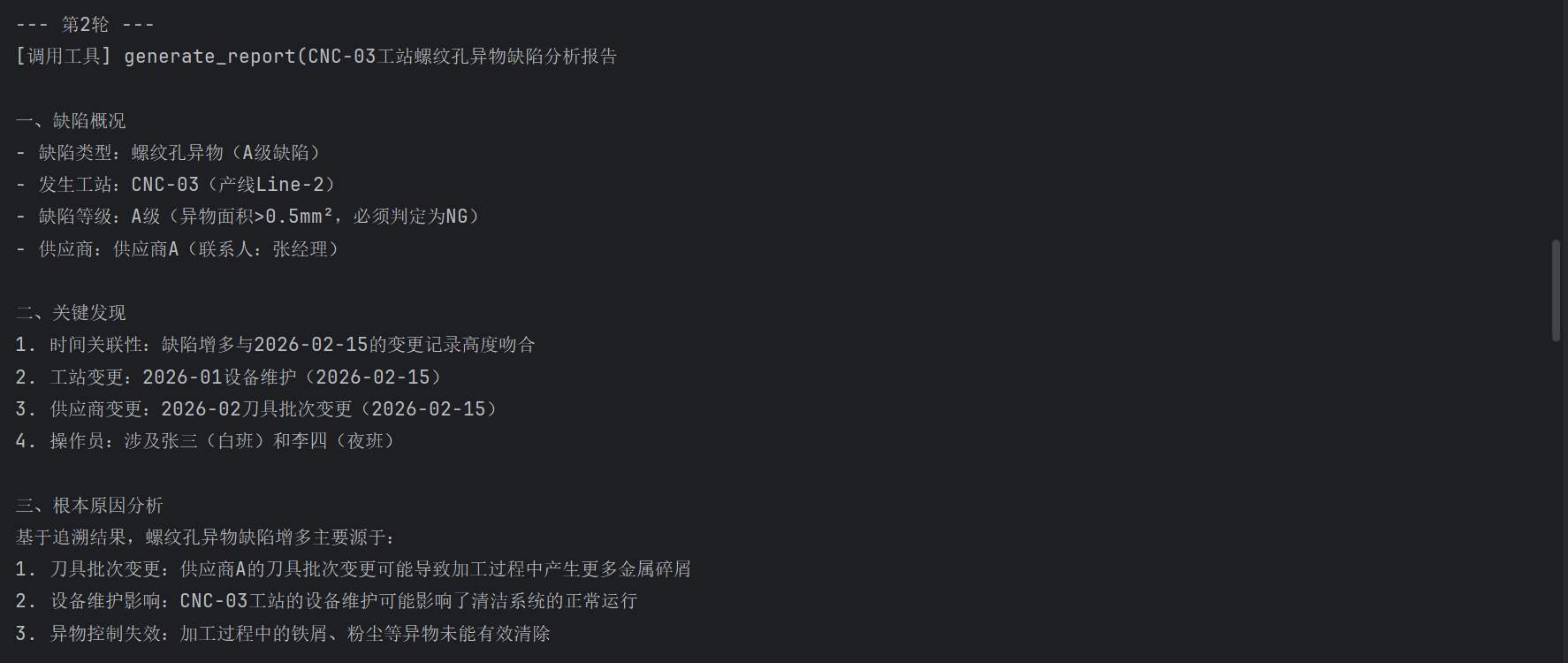
--- 第3轮 ---
[调用工具] generate_report(...)
[返回] 结构化质量分析报告...
--- 第4轮 ---
[最终输出] 完整的分析报告,包含根因分析和改善建议Agent自主完成了四轮推理:先追溯根因,再查标准,然后生成报告,最后综合输出。全程没有任何if-else告诉它该怎么做。


设计原则——Controllable, Observable, Explainable
在工业环境中部署AI Agent,必须满足三个原则:
Controllable(可控性):Agent的行为边界是确定的。它只能调用预定义的Tool集合,有最大轮次限制防止无限循环,敏感操作(比如实际修改产线参数)需要人工确认。这和我在AOI项目中给机械手设置软件限位是同一个思路。
Observable(可观测性):Agent的每一步推理都可追踪。每次调用了什么工具、传了什么参数、返回了什么结果,全部有日志。就像我在产线上做的结构化日志系统——每个检测步骤的输入输出都可追溯。
Explainable(可解释性):Agent能解释它为什么做出这个决定。ReAct模式天然可解释——每一步都有推理过程。这比我之前在AOI项目中AI检测结果附带置信度分数是同一个逻辑——不只给结果,还要给依据。
从工业软件到Agentic AI——我的思考
做这个项目的过程中,我发现工业软件开发和Agentic AI之间有很多共通之处:
| 工业软件概念 | Agentic AI对应 |
|---|---|
| 状态机调度 | Agent的规划循环 |
| 多机械手协调 | Multi-Agent系统 |
| AI检测 + 规则兜底 | LLM推理 + Fallback机制 |
| 结构化日志 | Agent的可观测性 |
| 安全限位 | Agent的可控性 |
| 置信度分数 | Agent的可解释性 |
从rule-based(规则驱动)到AI-driven(AI驱动),本质是把决策权从硬编码的if-else转移到了LLM的动态推理。但工业场景对可靠性的要求没有变——Agent必须可控、可观测、可解释。
后续改进方向
当前是Demo阶段,如果要实际部署还需要:
- 向量数据库换成持久化方案(如Milvus),支持文档更新
- Knowledge Graph用Neo4j替代NetworkX,支持更复杂的图查询
- 接入真实的MES/WMS数据源
- 加入模型评估和漂移检测
- Multi-Agent架构:质量分析Agent、物流Agent、设备维护Agent各司其职