工厂里的质量工程师经常遇到一个问题:检测标准分散在几十份文档里,出了问题要翻半天才能找到对应的处理流程。能不能让AI直接从文档里找答案?这篇文章记录了我用RAG架构构建工业文档问答系统的完整过程,并对比了DeepSeek和GLM两个模型的实际表现。
为什么要做这个
我在Apple供应链做AOI检测系统,日常需要查各种质量标准文档——螺纹孔缺陷怎么判定、AI检测故障了怎么处理、不同产品颜色检测要注意什么。这些信息都在文档里,但每次都要人工翻找。
直接把文档丢给大模型可以吗?不行,原因有两个:
- 大模型有上下文长度限制,几十份文档塞不进去
- 就算塞进去,大部分内容是噪音,回答反而不准确
RAG(检索增强生成)就是解决这个问题的——先从文档里检索最相关的段落,只把这些段落给大模型看,让它基于真实文档回答。
系统架构
用户提问
│
▼
┌──────────────────────────────────┐
│ 检索模块(Retrieval) │
│ 用户问题 → 向量化 → ChromaDB │
│ → 检索 top-k 最相关文档段落 │
└──────────────────────────────────┘
│
▼
┌──────────────────────────────────┐
│ 生成模块(Generation) │
│ 检索结果 + 对话历史 + 用户问题 │
│ → LLM 生成回答(附带引用来源) │
└──────────────────────────────────┘
│
▼
结构化回答 + 引用来源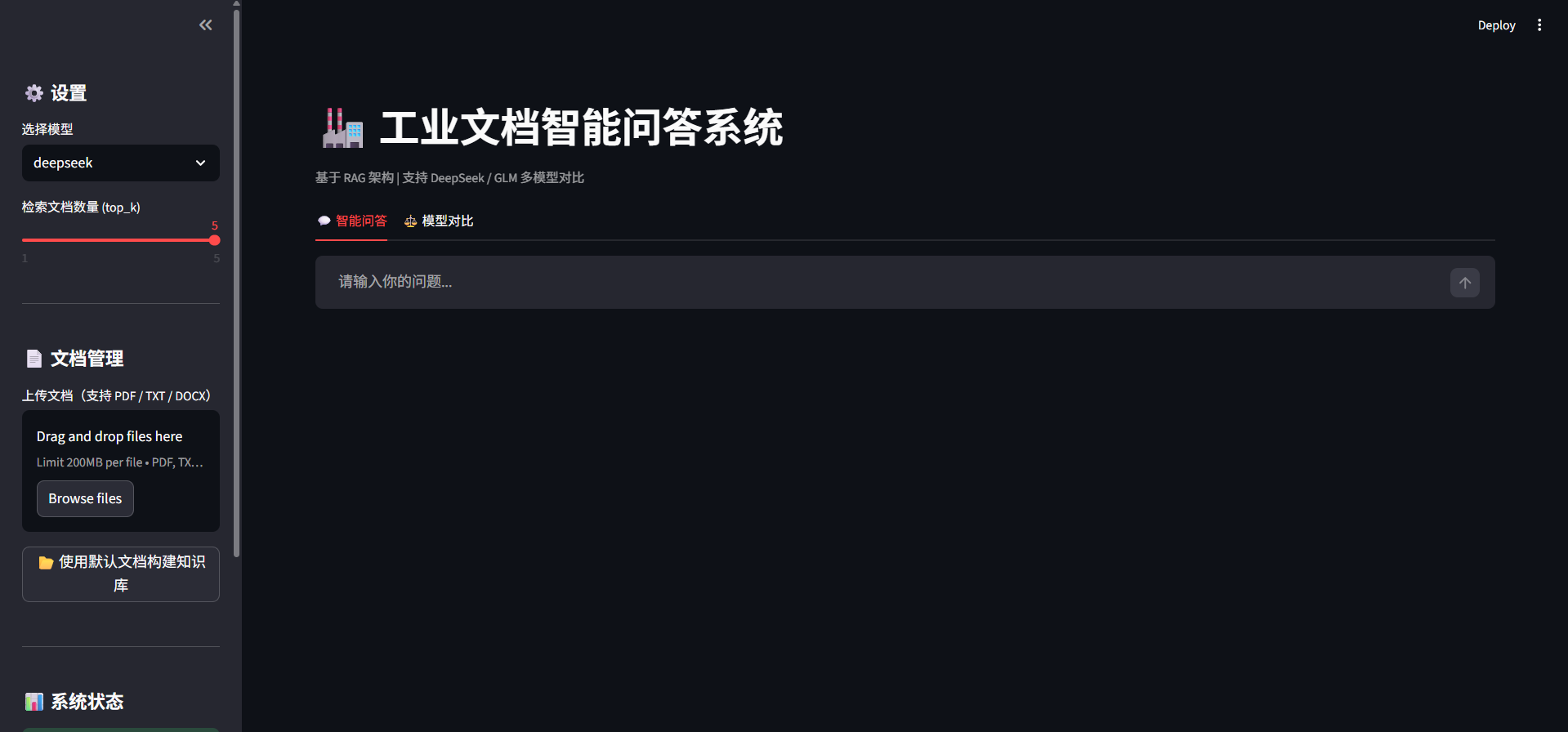
技术选型
| 组件 | 技术 | 选择理由 |
|---|---|---|
| LLM | DeepSeek / GLM-4.5-Air / GLM-4.6V | 多模型对比,验证RAG在不同模型下的表现 |
| Embedding | BAAI/bge-large-zh-v1.5 | 中文最强开源Embedding,1024维 |
| 向量数据库 | ChromaDB | 支持持久化存储,比FAISS更工程化 |
| 框架 | LangChain | 成熟的RAG生态,文档加载/切片/检索/问答链一站式 |
| 前端 | Streamlit | 快速搭建Web界面,适合Demo展示 |
| 文档解析 | PyPDF / python-docx | 支持PDF、Word、TXT三种格式 |
文档处理管线
RAG的第一步是把文档变成可检索的形式。
加载文档
系统支持三种格式,根据文件后缀自动选择加载器:
def load_single_file(file_path):
ext = os.path.splitext(file_path)[1].lower()
if ext == ".pdf":
loader = PyPDFLoader(file_path)
elif ext == ".txt":
loader = TextLoader(file_path, encoding="utf-8")
elif ext in [".docx", ".doc"]:
loader = Docx2txtLoader(file_path)
return loader.load()文本切片
长文档需要切成小段,每段作为一个检索单元:
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
separators=["\n\n", "\n", "。", ";", ",", " "]
)
chunks = splitter.split_documents(docs)这里有两个关键参数:
chunk_size=500:每段最多500字。太长检索精度下降(噪音多),太短上下文断裂(信息不完整)。500字在中文质量文档场景下是一个不错的平衡点。
chunk_overlap=100:相邻段落重叠100字。防止关键信息正好被切断在两段之间。比如一段话描述"A级缺陷的判定标准是…",如果正好从中间切开,两段都拿不到完整信息。
separators:优先按段落换行分割,其次按句号、分号,最后按逗号和空格。中文文档的自然断句比英文更重要。
向量化 + 存储
把文本块变成数字向量,存入ChromaDB:
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-large-zh-v1.5")
vectorstore = Chroma.from_documents(chunks, embeddings, persist_directory="chroma_db")选择bge-large-zh-v1.5的原因是它在中文语义检索任务上的表现目前是开源模型里最好的,1024维向量能够捕捉足够的语义信息。
RAG检索 + 问答
核心流程:用户提问 → 检索最相关的文档段落 → 把段落和问题一起给LLM → LLM基于文档回答。
# 检索
results = vectorstore.similarity_search_with_score(query, k=top_k)
# 构建Prompt
prompt = """根据以下参考文档回答问题。
要求:
1. 只基于参考文档回答,不要编造
2. 标注引用来源,例如 [引用1]
3. 文档中没有相关信息就明确告知
参考文档:{context}
用户问题:{question}"""
# LLM生成
response = llm.invoke(prompt)这里有一个重要设计:每条回答都附带引用来源。用户不仅能看到答案,还能看到这个答案是从哪份文档的哪段话得出的。这对工业场景尤其重要——质量判定必须有依据,不能是AI凭空编造的。
📸
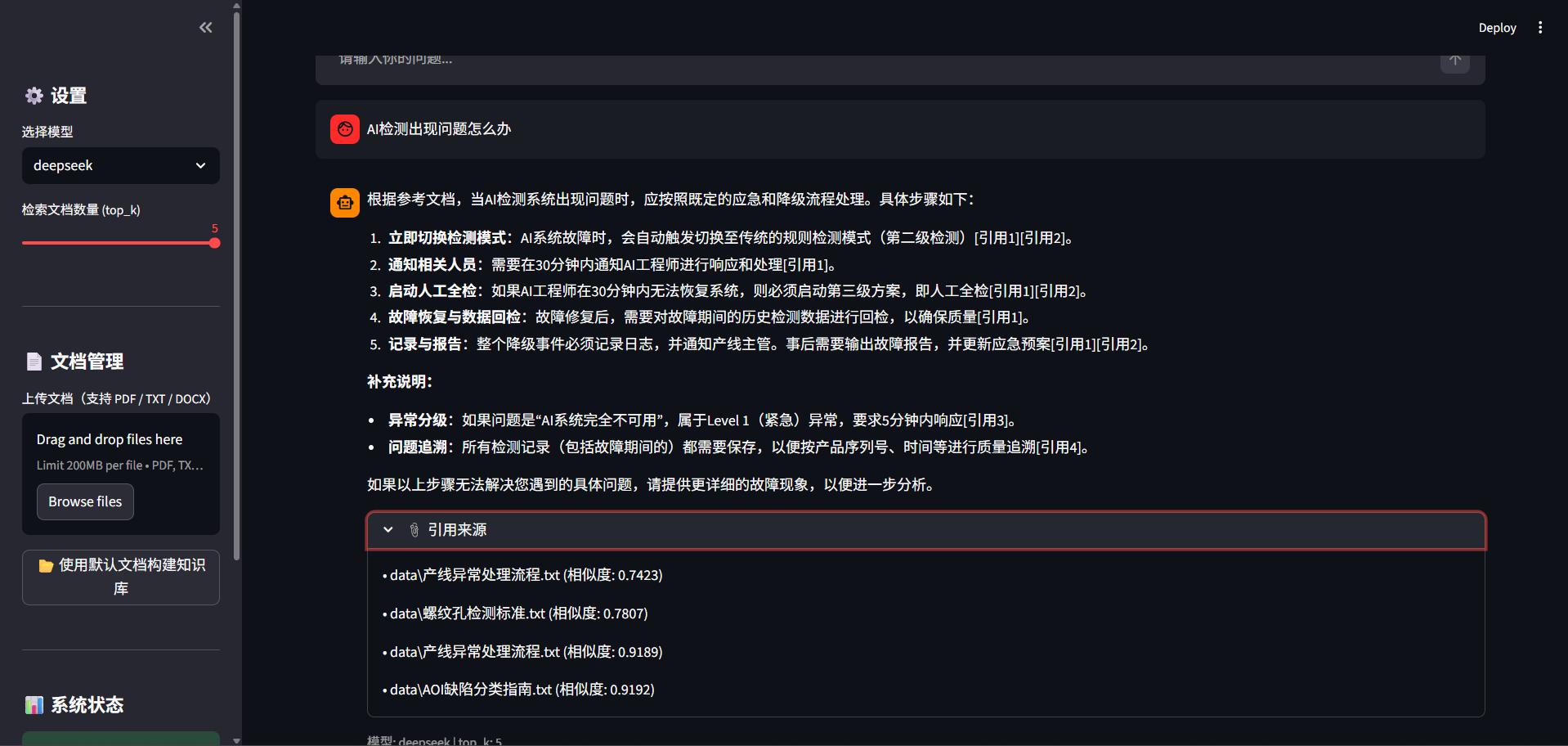
多轮对话
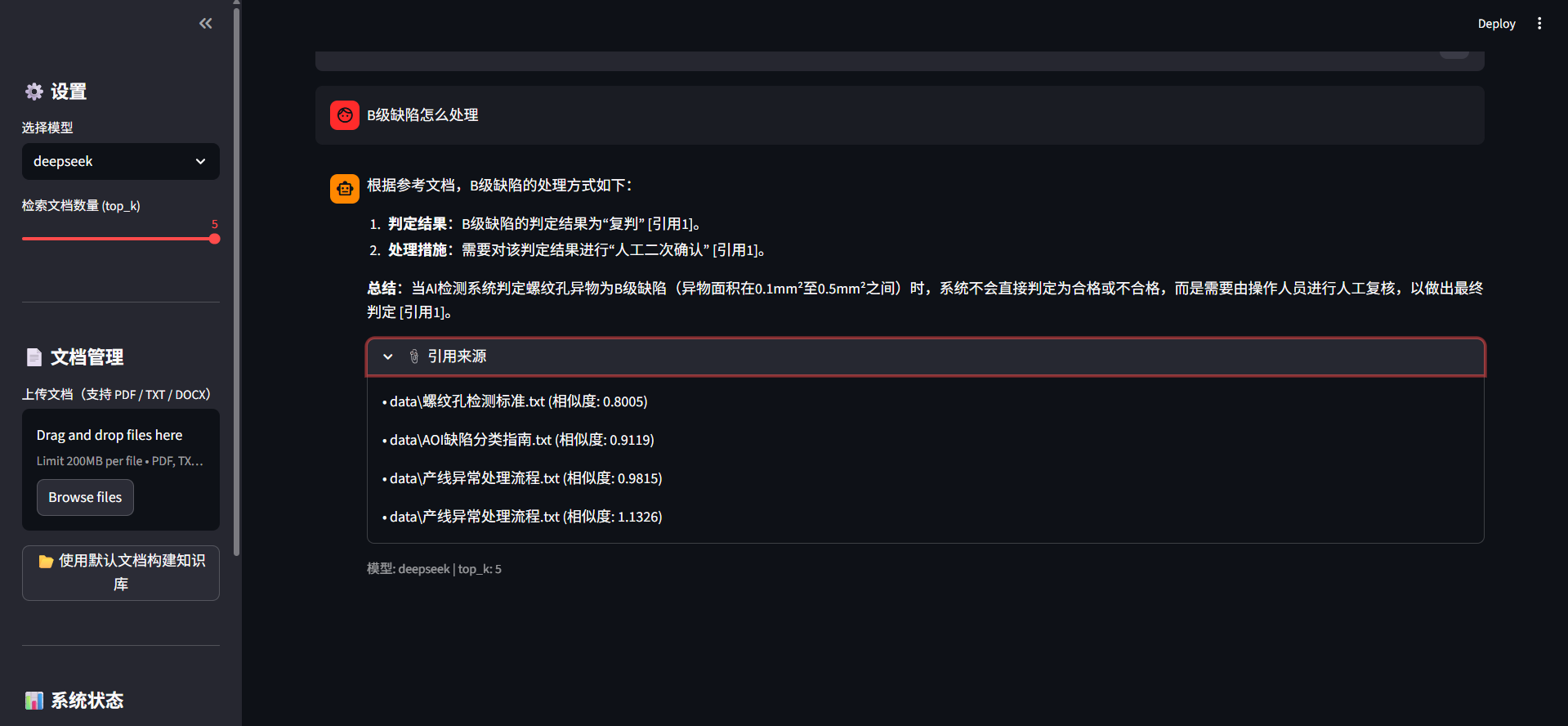
单轮问答有一个问题:用户追问时AI不知道上下文。
比如用户先问"螺纹孔异物怎么判定",然后追问"B级缺陷怎么处理"——如果没有对话记忆,AI不知道"B级缺陷"指的是螺纹孔异物的B级。
解决方案:在Prompt里加入对话历史。
class RAGAssistant:
def __init__(self):
self.chat_history = []
def ask(self, query):
# 检索文档
results = vectorstore.similarity_search_with_score(query, k=top_k)
# Prompt里同时传入对话历史和检索结果
response = llm.invoke({
"history": self.chat_history, # 之前聊了什么
"context": results, # 检索到的文档
"question": query # 当前问题
})
# 保存到历史
self.chat_history.append(HumanMessage(content=query))
self.chat_history.append(AIMessage(content=response.content))这样追问时LLM能看到之前的对话,理解"B级缺陷"的上下文。
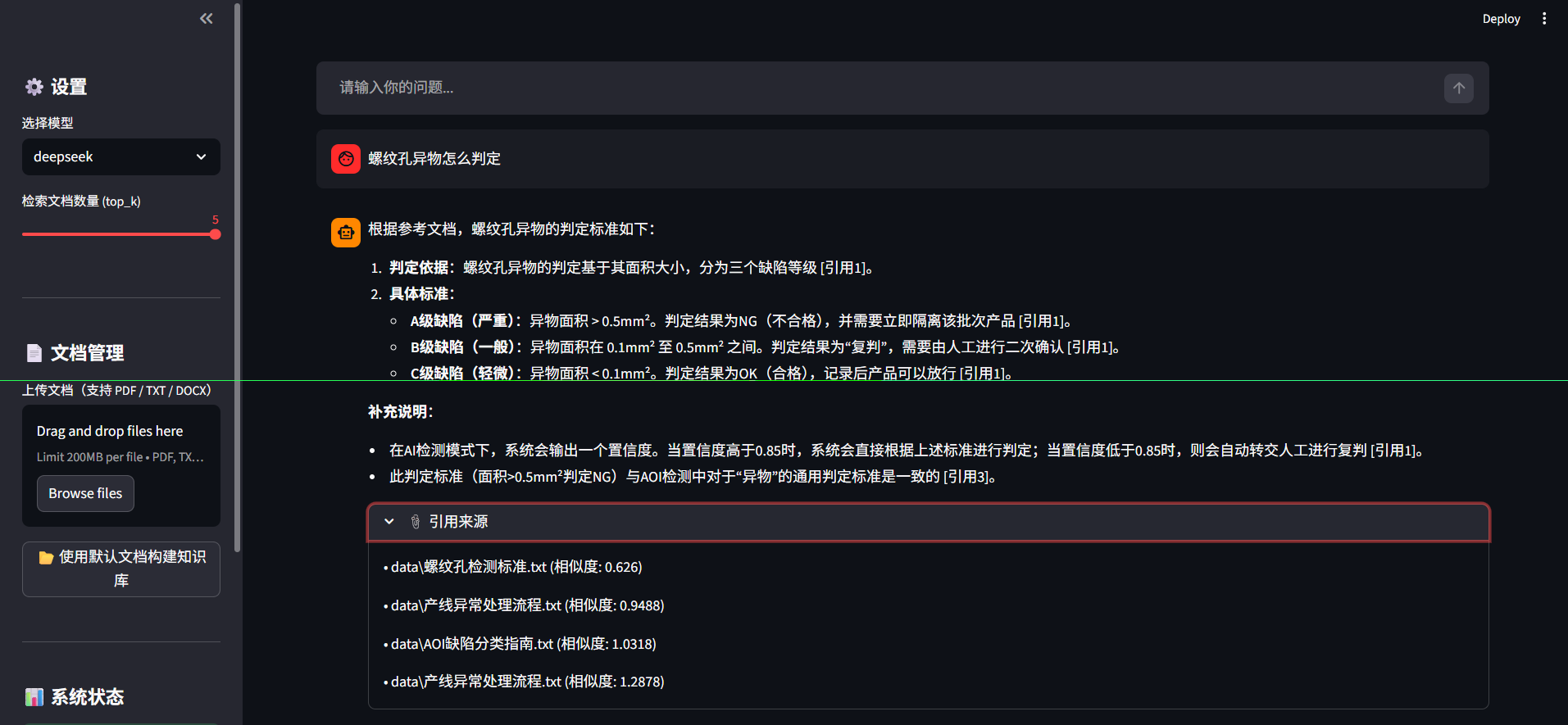
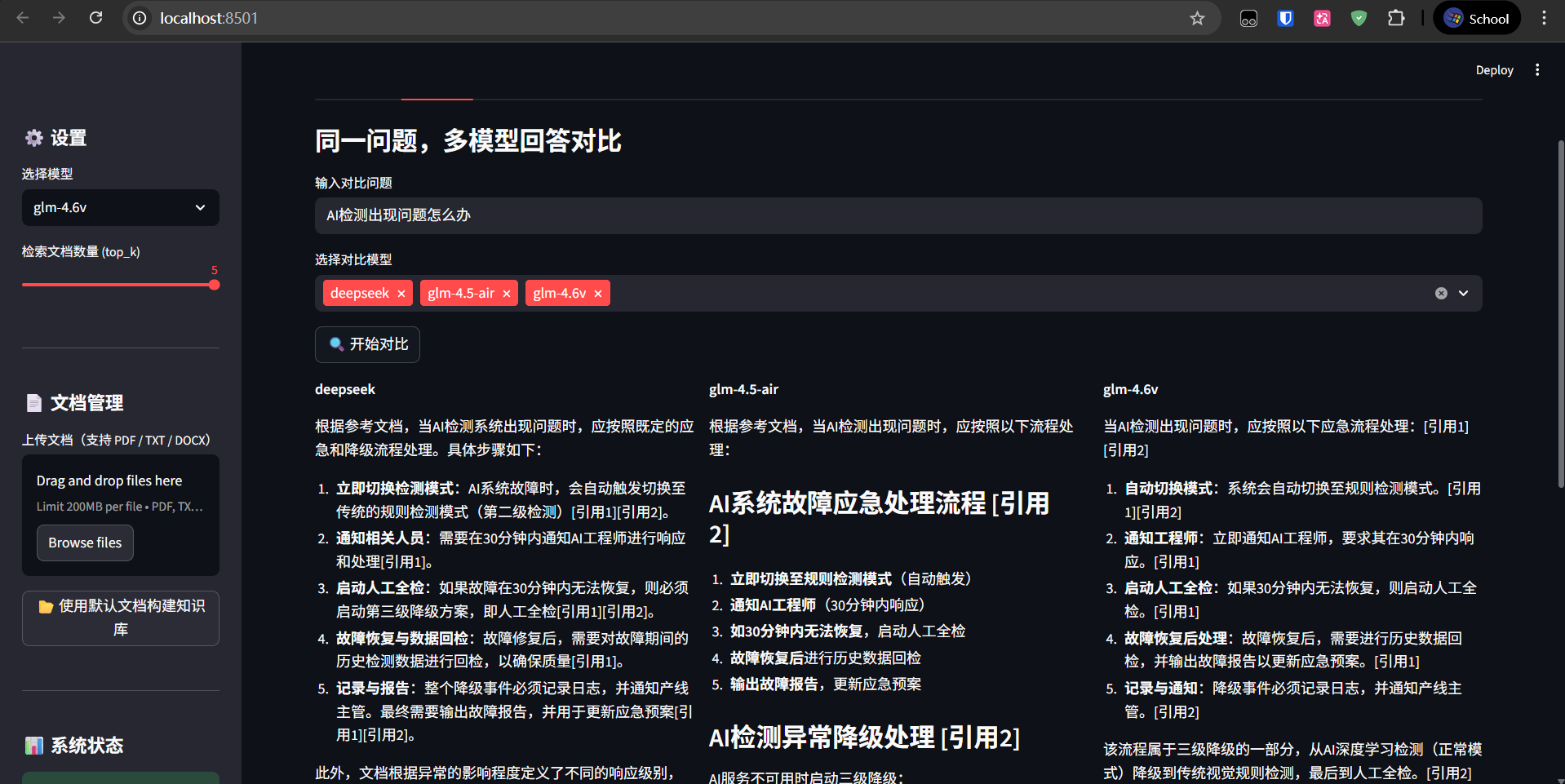
DeepSeek vs GLM 效果对比
同一个问题,同样的检索结果,分别交给DeepSeek和GLM回答,对比差异。
测试问题1:螺纹孔异物怎么判定?
DeepSeek:回答层次分明,先给判定标准(A/B/C三级),再补充AI检测参数,最后做综合说明。风格偏"教科书式",条理清晰。
GLM-4.5-Air:同样覆盖了三级标准和AI参数,但会额外扩展相关信息。风格偏"工程师式",信息更全面。
测试问题2:AI检测系统故障了怎么办?
DeepSeek:严格按照文档的处理流程回答,引用准确,不添加文档外的信息。
GLM-4.5-Air:除了流程步骤,还主动关联了异常分级(Level 1紧急),补充了更多上下文。
测试问题3:SN-2产品检测要注意什么?
DeepSeek:只提了两点(置信度阈值和曝光时间),简洁精准。
GLM-4.5-Air:除了核心两点,还扩展了光源配置和追溯要求,回答更完整但也更长。
总结对比
| 维度 | DeepSeek | GLM-4.5-Air |
|---|---|---|
| 回答风格 | 简洁精准,严格基于文档 | 详细全面,主动扩展关联信息 |
| 引用准确性 | 引用标注准确 | 引用标注准确 |
| 幻觉风险 | 低,不编造 | 偶尔扩展的信息超出文档范围 |
| 适用场景 | 需要精准判定的场景 | 需要全面分析的场景 |
top_k 检索数量对比
检索数量(top_k)直接影响回答质量:
| top_k | 效果 |
|---|---|
| 1 | 只看1段最相关的文档,回答精准但信息可能不完整 |
| 3 | 平衡精准和全面,大部分场景的最优选择 |
| 5 | 信息全面但可能引入不相关段落,增加噪音和幻觉风险 |
实测发现top_k=3是最佳平衡点:既能覆盖问题相关的核心信息,又不会引入太多噪音影响回答质量。
踩坑记录
1. Embedding模型选型
一开始用了all-MiniLM-L6-v2(英文模型),中文检索效果很差——"螺纹孔异物"和"缺陷检测标准"的相似度很低。换成bge-large-zh-v1.5后检索准确率明显提升。中文场景一定要用中文Embedding模型。
2. chunk_size的选择
最初设了1000字,发现检索到的段落太长,里面很多无关信息。改成300字又太短,一段完整的标准说明被拆成了两半。最终500字+100字重叠是比较好的平衡。
3. ChromaDB vs FAISS
上一个项目用了FAISS,这次换成ChromaDB。区别是FAISS每次都要从内存加载,ChromaDB支持持久化存储到磁盘,重启后不需要重新构建。对于需要频繁更新文档的场景,ChromaDB更实用。
4. 对话历史过长
多轮对话后,历史记录越来越长,Prompt超出上下文限制。解决方案是只保留最近5轮对话,更早的历史丢弃。
后续改进方向
- 支持更多文档格式(Excel、Markdown)
- 检索策略优化(混合检索:关键词 + 语义)
- 添加用户反馈机制(回答有用/没用),用于评估检索质量
- 部署到云端,支持多人同时使用
项目地址:GitHub – rag-doc-qa
